- سبک زندگی یاهو
- علم در بازی: نشانگر آب کلم قرمز
- در اینجا آمده است که چگونه می توانید رمزنگاری خود را از binance به metamask منتقل یا پس بگیرید
- حق بیمه ریسک بازار
- RT Active Global Trend t
- صرافی های متمرکز و غیرمتمرکز ارزهای دیجیتال - مقایسه!
- عمق بازار فارکس ، ابزاری مفید برای معامله گران فارکس
- فرا گرفتن. خودکارتجارت مستر
- صف به quaff؟همه گیر برای انحصار مشروبات الکلی ایالت سوئد مشکل ایجاد می کند
- نمونه موارد تست - معاملات سهام چند بازاری

آخرین مطالب
امکانات وب


در این فصل 48 مقدمه ای بر پیچیدگی های داده های مکانی و مدل سازی فضایی و زمانی ارائه شده است. برای مدل سازی ، ما چارچوب ثابت رتبه کریگینگ (FRK) را که توسط Cressie و Johannesson (2008) تهیه شده است ، در نظر می گیریم. این امکان ساخت یک مدل اثرات تصادفی فضایی را در یک دامنه فضایی گسسته فراهم می کند. مزایای اصلی این رویکرد شامل ظرفیت: (1) کار با مجموعه داده های بزرگ ، (2) مقیاس بندی می شود.(3) پیش بینی های خود را بر اساس تکنیک های جبری خطی پراکنده ایجاد کنید ، و (4) برآورد عدم اطمینان وضوح در مقیاس خوب تولید می کنند.
محتوای این فصل براساس:
Wikle ، Zammit-Mangion و Cressie (2019) ، کتابی که اخیراً منتشر شده است که نمای کلی از رویکردهای آماری موجود در مدل سازی فضا-زمانی و بسته های R را ارائه می دهد.
Zammit-Mangion and Cressie (2017) ، که چارچوب آماری و بسته R را برای مدل سازی فضا-زمانی مورد استفاده در این فصل معرفی می کند.
این فصل بخشی از یادداشت های تجزیه و تحلیل فضایی است ، تلفیقی که به عنوان مخزن GitHub میزبان است که می توانید از چند طریق به آن دسترسی پیدا کنید:
- به عنوان بارگیری یک پرونده . zip که شامل تمام مواد است.
- به عنوان یک وب سایت HTML.
- به عنوان یک سند PDF
- به عنوان یک مخزن GitHub.
10. 1 وابستگی
در این فصل از کتابخانه های زیر استفاده می شود: اطمینان حاصل کنید که آنها قبل از بارگیری آنها در اجرای قطعه کد زیر بر روی دستگاه شما 49 نصب شده اند:
10. 2 داده
برای این فصل ، ما از داده ها در مورد:
COVID-19 مواردی را از 30 ژانویه 2020 تا 21 آوریل 2020 از بهداشت عمومی انگلیس از طریق داشبورد Gov. uk تأیید کرد.
ویژگی های جمعیت مقیم از سرشماری سال 2011 ، که از دفتر آمار ملی موجود است. وت
شاخص سال 2019 داده های محرومیت چندگانه (IMD) از Gov. uk و توسط وزارت مسکن ، جوامع و دولت محلی منتشر شده است. داده ها در سطح Authority محلی محلی ONS (UTLA) قرار دارند - همچنین به عنوان ایالت ها و مقامات واحد شناخته می شوند.
برای لیست کاملی از متغیرهای موجود در مجموعه داده های مورد استفاده در این فصل ، به پرونده README در پوشه داده STA مراجعه کنید. 50قبل از اینکه داده ها را به دست بیاوریم ، مفاهیم مهمی وجود دارد که باید معرفی شوند. آنها یک چارچوب مفید برای درک ساختار پیچیده داده های فضایی و زمانی ارائه می دهند. بیایید با اولویت بندی اهمیت تجزیه و تحلیل فضا-زمانی شروع کنیم.
10. 3 چرا تجزیه و تحلیل فضایی-زمانی؟
بررسی الگوهای مکانی فرآیندهای انسانی همانطور که تاکنون در این کتاب انجام داده ایم ، فقط یک نمایش ناقص جزئی از این فرایندها را ارائه می دهد. این امکان درک تکامل زمانی این فرآیندها را فراهم نمی کند. فرآیندهای انسانی در فضا و زمان تکامل می یابد. تحرک انسانی یک فرایند جغرافیایی ذاتی است که در طول روز تغییر می کند و قله های ساعات عجله و تمرکز زیاد به سمت اشتغال ، آموزش و مراکز خرده فروشی است. قرار گرفتن در معرض آلودگی هوا با شرایط آب و هوایی محلی و انتشار و غلظت آلاینده های جوی که به مرور زمان نوسان می کنند. میزان گسترش بیماری در فضا متفاوت است و ممکن است با گذشت زمان تغییر کند ، همانطور که در طول شیوع فعلی مشاهده کردیم ، با روند صاف یا رو به کاهش در استرالیا ، نیوزیلند و کره جنوبی اما گسترش سریع در انگلستان و ایالات متحده. فقط با در نظر گرفتن زمان و مکان در کنار هم می توانیم چگونگی تغییر نهادهای جغرافیایی با گذشت زمان و چرا تغییر آنها را مورد بررسی قرار دهیم. بخش بزرگی از چگونگی و چرایی چنین تغییراتی ناشی از تعامل در فضا و زمان و فرآیندهای متعدد است. درک گذشته برای آگاهی از درک ما از حال و پیش بینی در مورد آینده ضروری است.
10. 3. 1 ساختار داده های فضا-زمانی
اولین عنصر اصلی درک ساختار داده های فضایی-زمانی است. داده های فضا-زمانی شامل دو بعد است. در یک انتها ، ابعاد زمانی داریم. در تجزیه و تحلیل کمی ، از داده های سری زمانی برای ضبط فرآیندهای جغرافیایی در فواصل منظم یا نامنظم استفاده می شود. یعنی در مقیاس زمانی مداوم (روزانه) یا گسسته (فقط در صورت وقوع یک رویداد). در انتهای دیگر ، ابعاد مکانی داریم. ما غالباً از داده های مکانی به عنوان تجمع زمانی یا حالت های منجمد موقتی (یا "عکس های فوری") یک فرآیند جغرافیایی استفاده می کنیم - این همان کاری است که ما تاکنون انجام داده ایم. به یاد بیاورید که داده های مکانی می توانند در واحدهای مختلف جغرافیایی ، مانند دره یا شبکه ، نقاط ، جریان یا مسیرها ضبط شوند - به سخنرانی مقدماتی در هفته 1 مراجعه کنید. دو استثناء قابل توجه در R بسته های Traminer (گابادینیو و همکاران 2009) و Spacetime (Pebesma و دیگران 2012) است. ما از تعاریف کلاس تعریف شده در Spacetime بسته R استفاده می کنیم. این کلاس ها مواردی را که برای داده های مکانی در SP و داده های سری زمانی در XTS استفاده می شود ، گسترش می دهد. در مرحله بعد ، مقدمه ای مختصر در مورد مفاهیمی که تفکر در مورد ساختارهای داده فضایی و زمانی را تسهیل می کند.
10. 3. 1. 1 نوع جدول
داده های فضایی-زمانی می توانند به عنوان سه نوع اصلی جداول مفهوم سازی شوند:
در سراسر زمان: جدول که در آن ستون ها با نقاط زمانی مختلف مطابقت دارد
در سطح فضا: جدول که در آن ستون ها با موقعیت مکانی مختلف مطابقت دارد
قالبهای طولانی: جدول که در آن هر جفت ستون ردیف با یک زمان خاص و مکان مکانی (یا مختصات فضا) مطابقت دارد
توجه داشته باشید که داده ها در قالب طولانی فضا هستند زیرا مختصات مکانی و ویژگی های زمانی برای هر نقطه داده مورد نیاز است. با این حال ، داده های موجود در این قالب از طریق بسته هایی مانند dplyr و tidyr ، دستکاری نسبتاً آسان است و با استفاده از GGPLOT2 تجسم می کنند. این بسته ها برای کار با داده ها در قالب طولانی طراحی شده اند.
10. 3. 1. 2 نوع شیء فضایی-زمانی
برای ادغام داده های فضا-زمانی ، اشیاء فضایی-زمانی مورد نیاز است. ما چهار فریم مختلف مکانی (STF) یا اشیاء مختلف را در نظر می گیریم که می توانند از طریق بسته بندی بسته بندی تعریف شوند:
شبکه کامل (STF): یک شیء حاوی داده ها در تمام مکان های ممکن در تمام نقاط زمانی در یک دنباله از داده ها.
شبکه پراکنده (STS): یک شیء شبیه به STF اما فقط شامل ترکیب داده های فضا-زمان غیر از بین می رود.
نامنظم (STI): یک شی با ساختار داده نامنظم فضا-زمان ، که در آن هر نقطه یک مختصات مکانی و یک تمبر زمان اختصاص می یابد.
مسیرهای ساده (STT): یک شیء شامل دنباله ای از نقاط فضا-زمان است که مسیرها را تشکیل می دهند.
جزئیات بیشتر در مورد این سازه های فضایی-زمانی ، ساخت و ساز و دستکاری ، به Pebesma و دیگران (2012) مراجعه کنید. نظریه کافی ، بگذارید کد کنیم!
10. 4 درگیری داده ها
در این بخش پیچیدگی های رسیدگی به داده های فضایی و زمانی نشان داده شده است. این در مورد شیوه های خوب در دستکاری داده ها و ساخت یک شیء داده نامنظم زمان (STIDF) در زمان فضا بحث می کند. سه مورد اصلی برای تعریف یک شیء STFDF عبارتند از:
یک قاب داده در قالب طولانی یعنی یک قاب داده جفت زمان مکان یابی داشته باشید
یک تمبر زمان را تعریف کنید
با نشان دادن مختصات مکانی و زمانی ، شیء فضایی و زمانی کلاس stidf را بسازید
اکنون می توانیم تمام داده های مورد نیاز را بخوانیم. در حالی که ما می توانیم همه داده ها را در یک قاب داده واحد داشته باشیم ، برای شناسایی اشیاء داده جداگانه مفید خواهید بود:
این اشیاء داده با LOC ها ، زمان و covid19 و سرشماری در زیر مطابقت دارند. در طول فصل متوجه خواهید شد که بسته به عملکرد ، ما بین قاب های مختلف داده در هنگام کانتی تغییر می کنیم.
اگر ساختار داده ها را از طریق سر و STR کشف کنیم ، می توانیم ببینیم که داده های روزانه و تجمعی جدید Covid-19 را برای 150 واحد فضایی (یعنی UTLA) بیش از 71 نقطه زمانی از 30 ژانویه تا 21 آوریل داریم. ما همچنین برای طیف وسیعی از ویژگی ها داده های سرشماری و IMD داریم.
هنگامی که ما ساختار داده ها را درک کردیم ، ابتدا باید تأیید کنیم که آیا داده های COVID19 در قالب گسترده یا طولانی هستند یا خیر. خوشبختانه آنها در قالب طولانی هستند. در غیر این صورت ، ما نیاز به تبدیل داده ها از قالب گسترده به طولانی داریم. توابع مفید برای دستیابی به این هدف شامل Pivot_Longer (Pivot_Longer) است که در بسته Tidyr جمع آوری (گسترش) را پشت سر گذاشته است. توجه داشته باشید که قاب داده COVID19 دارای 10،650 مشاهده (یعنی ردیف ها) است. یعنی 150 UTLAS * 71 مشاهدات روزانه.
سپس یک تمبر زمان منظم را برای داده های زمانی خود تعریف می کنیم. ما برای انجام این کار از بسته Lubritate استفاده می کنیم. یک مزیت اصلی لوبیدر این است که به طور خودکار جداکننده های مشترک مورد استفاده در هنگام ضبط تاریخ را تشخیص می دهد ("-" ، "/" ، "." و ""). در نتیجه ، شما فقط برای تعیین عملکرد تجزیه و تحلیل اعمال شده باید روی مشخص کردن ترتیب عناصر تاریخ تمرکز کنید. در زیر ساختار داده های زمانی خود را بررسی می کنیم ، یک تمبر زمان را تعریف می کنیم و متغیرهای جداگانه ای را برای روزها ، هفته ها ، ماه ها و سال ایجاد می کنیم.
توجه داشته باشید که کار با خرما می تواند یک کار پیچیده باشد. بحث خوب در مورد این پیچیدگی ها در اینجا ارائه شده است.
پس از تعریف تمبر زمان ، ما باید اطلاعات مکانی موجود در Shapefile خود را اضافه کنیم تا یک قاب داده فضایی و زمانی ایجاد شود.
ما اکنون تمام مؤلفه ها را برای ساختن یک شیء فضایی-زمانی از کلاس Stidf با استفاده از Stidf از بسته Spacetime داریم:
اکنون متغیرهای سرشماری و IMD را اضافه می کنیم. برای اهداف این فصل ، ما فقط تعداد کل جمعیت و تعداد طولانی مدت جمعیت بیمار یا معلول را اضافه می کنیم. می توانید با اضافه کردن نام آنها در عملکرد انتخاب ، متغیرهای بیشتری را اضافه کنید.
10. 5 کاوش در مورد داده های فضایی-زمانی
اکنون تمام داده های مورد نیاز را در اختیار داریم. در این بخش روشهای مختلف تجسم داده ها قبل از بررسی ابعاد کلیدی داده ها نشان داده شده است. هر دوی این نوع اکتشافات می توانند چالش برانگیز باشند زیرا یک یا چند بعد در فضا و یک در زمان نیاز به بازجویی دارند.
10. 5. 1 تجسم
در داده های فضا-زمانی متن ، اولین چالش تجسم داده ها است. تجسم بیش از دو بعد از داده های فضایی-زمانی ، بنابراین تهیه یا جمع آوری داده ها در ابعاد ، استفاده از رنگ یا ایجاد انیمیشن ها در طول زمان مفید است. قبل از کاوش در داده ها ، باید متغیر اصلی مورد علاقه خود را تعریف کنیم. یعنی تعداد موارد تأیید شده COVID-19 در هر 100000 نفر. ما همچنین تعداد تجمعی موارد تأیید شده COVID-19 را در 100000 نفر محاسبه می کنیم زیرا ممکن است در برخی از تحلیل ها مفید باشد.
FISRT متغیر ایجاد شده برای تجزیه و تحلیل:
10. 5. 1. 1 توطئه های مکانی
یکی از راه های تجسم داده ها استفاده از توطئه های مکانی است. یعنی عکسهای فرایند جغرافیایی برای یک دوره زمانی معین. داده ها را می توان با استفاده از توطئه های Clorepret ، کانتور یا سطح به روش های مختلف ترسیم کرد. هدف اصلی این نقشه ها درک این است که چگونه میزان کلی تغییرات مکانی و الگوهای محلی غلظت مکانی با گذشت زمان تغییر می کند. در زیر ما تعداد هفتگی موارد تأیید شده COVID-19 را در 100000 نفر تجسم می کنیم.
توجه داشته باشید که هفته ها از 5 تا 16 متغیر است زیرا آنها به هفته های تقویم مراجعه می کنند. هفته 5 تقویم زمانی است که اولین پرونده Covid-19 در انگلیس گزارش شده است.
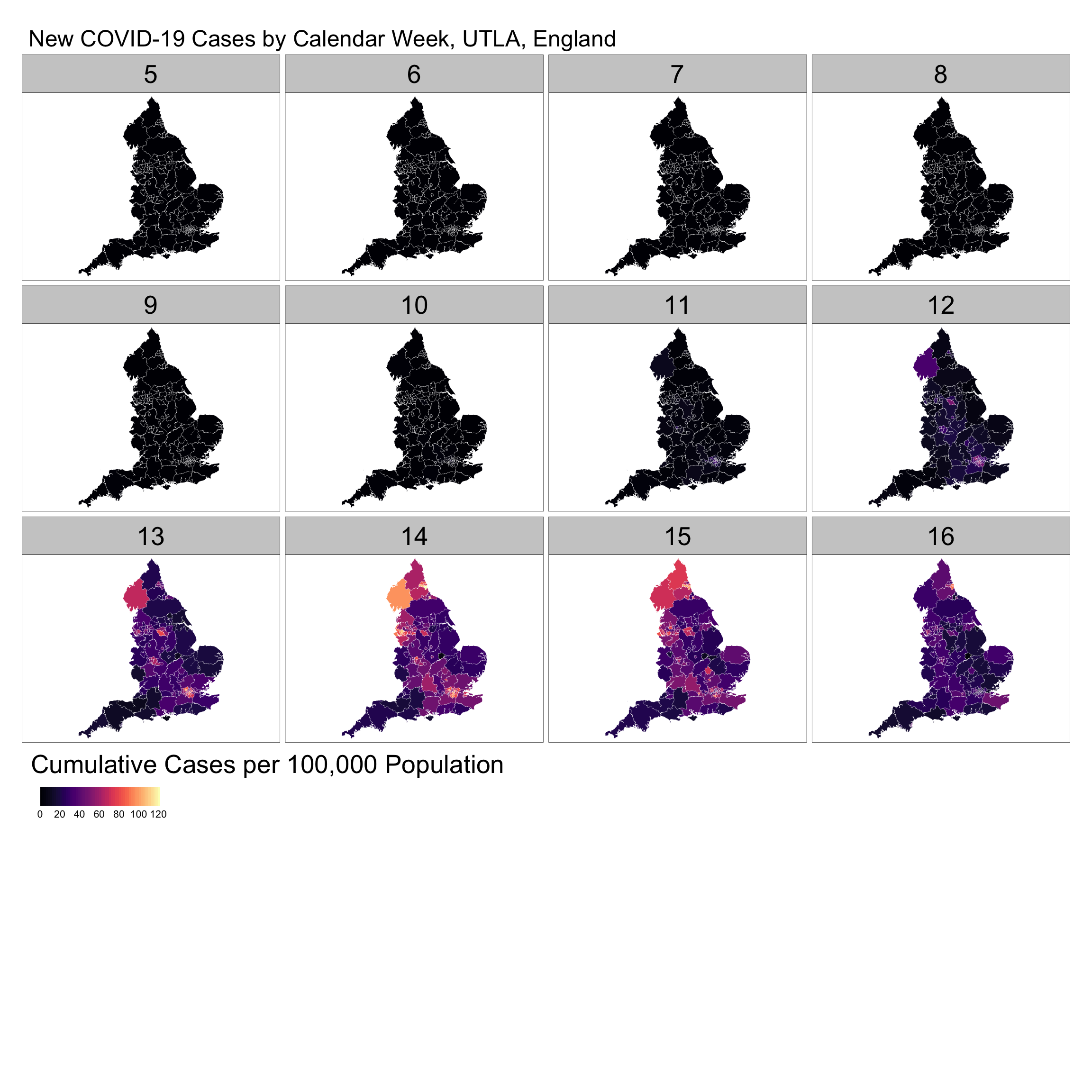
سری نقشه ها الگوی پایدار از موارد کم گزارش شده از هفته های تقویم 5 تا 11 را نشان می دهد. از هفته 12 تعدادی از نقاط داغ پدیدار شد ، به ویژه در لندن ، بیرمنگام ، کامبریا و متعاقباً در اطراف لیورپول. به نظر می رسد شدت موارد جدید از هفته 15 کاهش یافته است. با این حال ، توجه به این نکته حائز اهمیت است که نمایشگاه هفته شانزدهم فقط دو روز گزارش شده است.
10. 5. 1. 2 توطئه های سری زمانی
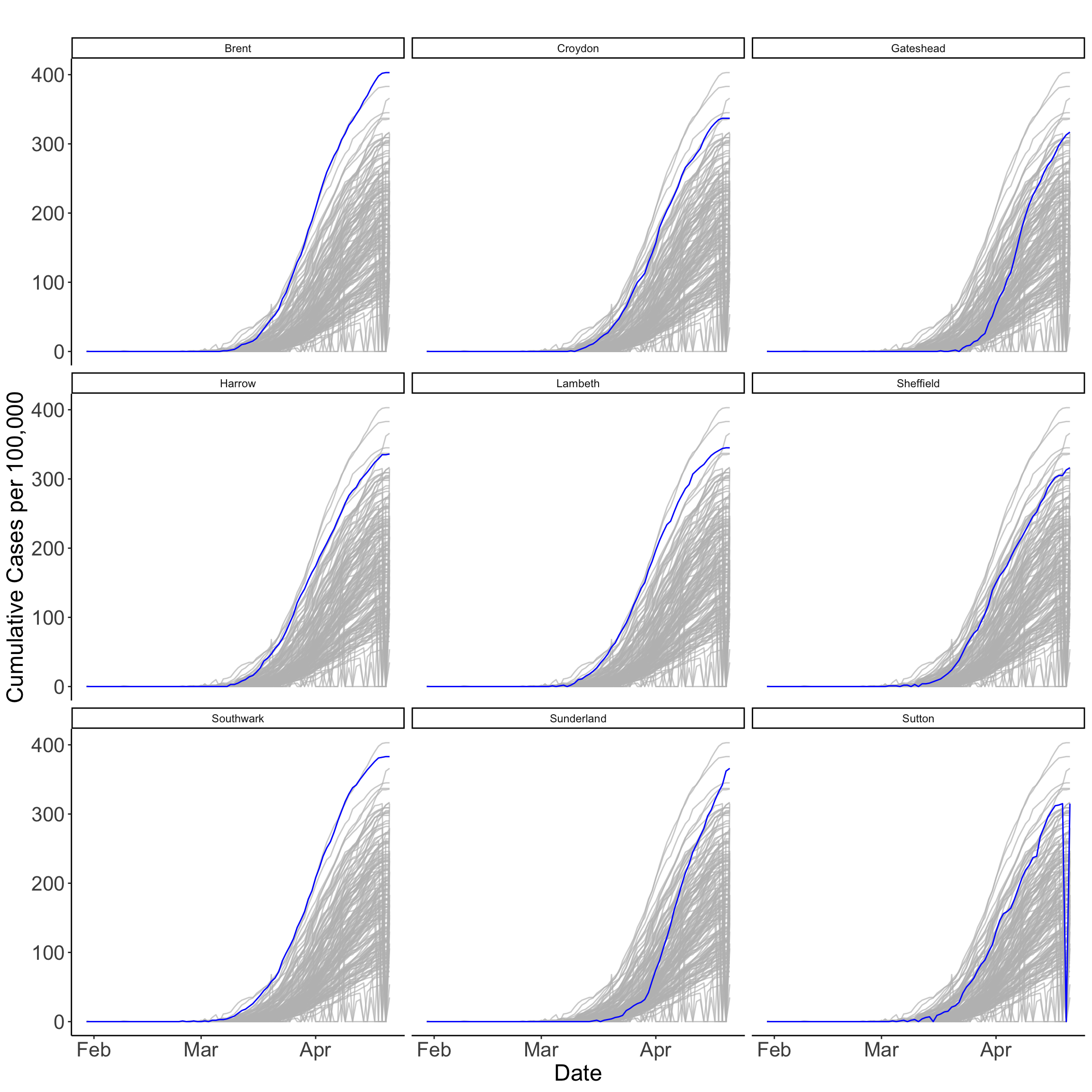
از توطئه های سری زمانی می توان برای ضبط ابعاد متفاوتی از فرآیند در تجزیه و تحلیل استفاده کرد. از آنها می توان برای درک بهتر تغییرات در یک مکان مشاهده ، تجمع مشاهدات یا چندین مکان به طور همزمان با گذشت زمان استفاده کرد. ما تعداد تجمعی موارد Covid-19 را در 100000 نفر برای UTLAS گزارش بیش از 310 مورد ترسیم می کنیم. این توطئه ها UTLAS را در لندن ، نیوکاسل و شفیلد که بیشترین تعداد موارد COVID-19 را گزارش می کنند ، شناسایی می کنند. این توطئه ها همچنین نشان می دهد که با برخی اختلافات ، افزایش مداوم در تعداد موارد وجود داشته است. در حالی که موارد از اواسط مارس به طور پیوسته در برنت و Southwark افزایش یافته است ، این افزایش در ساندرلند ناگهانی تر شده است. این توطئه ها همچنین یک مورد احتمالی گزارش نادرست در ساتون را در پایان این سریال نشان می دهد.
10. 5. 1. 3 توطئه Hovmöller
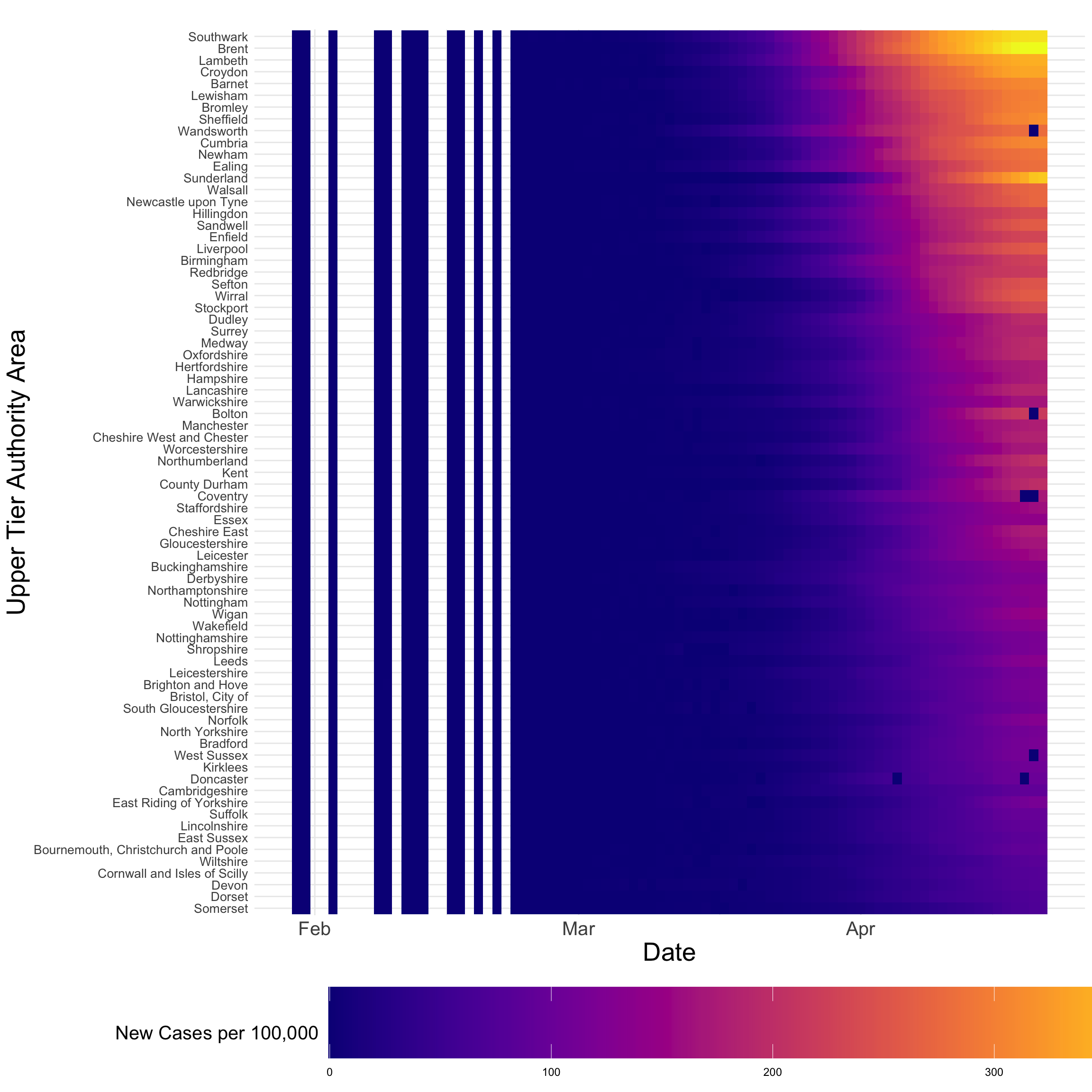
تجسم جایگزین یک طرح Hovmöller است - که گاهی به عنوان نقشه گرما شناخته می شود. این یک نمایش دو بعدی فضا است که در آن فضا در یک بعد در برابر زمان فرو می رود. اگر داده ها بر روی یک شبکه فضا-زمان تنظیم شوند ، توطئه های Hovmöller به راحتی قابل تولید هستند. با این حال ، این به ندرت اینگونه است. خوشبختانه ما GGPLOT داریم! که می تواند در صورت لزوم دوباره تنظیم مجدد داده ها انجام شود. در زیر ما یک طرح Hovmöller برای UTLAS با جمعیت مقیم بیش از 260،000 تولید می کنیم. این طرح روشن می کند که دوره بحرانی گسترش COVID-19 در ماه آوریل با وجود اجرای یک سری اقدامات فاصله اجتماعی اجتماعی توسط دولت بوده است.
10. 5. 1. 4 توطئه های تعاملی
تجسم های تعاملی روشهای بسیار مؤثر برای درک داده های فضایی و زمانی را تشکیل می دهند و اکنون آنها نسبتاً در دسترس هستند. تجسم های تعاملی باعث می شود یک تجربه غیرقانونی داده بیشتر باشد و بدون نیاز به متوسل شدن به اسکریپت ، کاوش در مورد داده ها را امکان پذیر کند. در اینجا وقتی استفاده از TMAP می درخشد ، زیرا نه تنها به راحتی نقشه های استاتیک خوب بلکه نقشه های تعاملی را نیز امکان پذیر می کند! در زیر نقشه تعاملی برای یک عکس فوری از داده ها (یعنی 2020-04-14) تولید می شود ، اما با کمی لایه های کار می توان برای نمایش چندین برش زمانی داده ها اضافه کرد.
برای مشاهده نقشه در دستگاه های محلی خود ، تکه کد را در زیر حذف علامت # اجرا کنید.
ابزارهای تجسم داده های جایگزین انیمیشن ها ، تلسکوپ و براق هستند. انیمیشن ها را می توان با ترسیم داده های فضایی قاب به قاب و سپس به صورت توالی در کنار هم قرار داد. بسته های مفید R Giganimate و TMAP! به Lovelace ، Nowosad و Muenchow (2020) مراجعه کنید. توجه داشته باشید که ایجاد انیمیشن ها ممکن است به وابستگی های خارجی نیاز داشته باشد. از این رو ، آنها در اینجا گنجانده شده اند. هر دو Telliscope و براق روشهای مفیدی برای تجسم مجموعه داده های بزرگ فضایی-زمانی به روش های تعاملی هستند. برخی از تلاش ها برای استقرار این ابزارها لازم است.
10. 5. 2 تجزیه و تحلیل اکتشافی
علاوه بر تجسم داده ها ، ما اغلب می خواهیم خلاصه عددی داده ها را بدست آوریم. باز هم ، روشهای نوآورانه برای کاهش ابعاد ذاتی داده ها و بررسی ساختار وابستگی و روابط بالقوه در زمان و مکان مورد نیاز است. ما تجسم از وسایل مکانی و زمانی تجربی ، ساختار وابستگی و برخی از تجزیه و تحلیل سری زمانی را در نظر می گیریم.
10. 5. 2. 1 معنی
میانگین مکانی تجربی
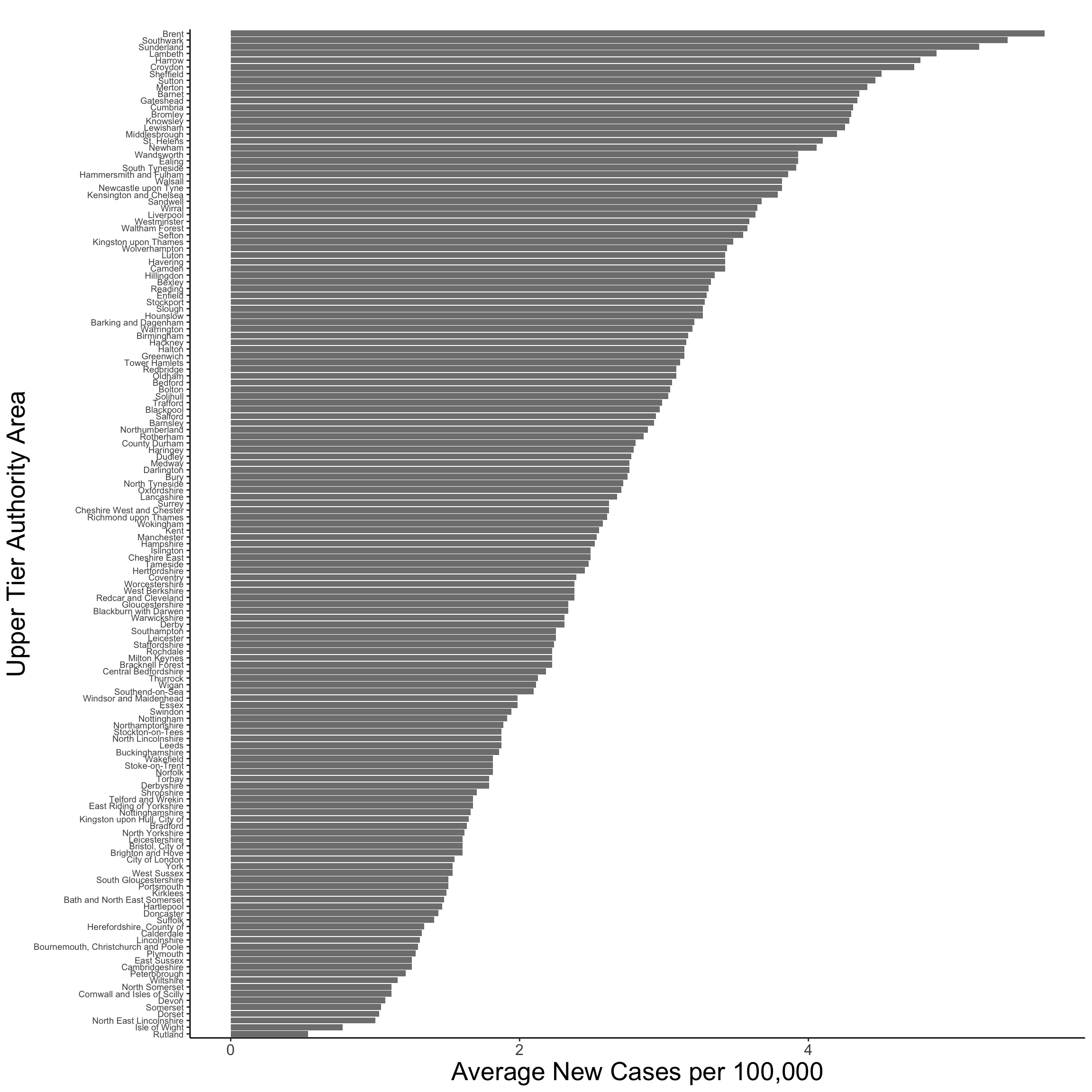
میانگین مکانی تجربی برای یک مجموعه داده را می توان با میانگین در طول زمان برای یک مکان بدست آورد. در مورد ما ، ما می توانیم میانگین مکانی تجربی را با میانگین نرخ روزانه موارد جدید Covid-19 برای UTLA ها بین 30 ژانویه و 21 آوریل محاسبه کنیم. این نشان می دهد که برنت ، Southwark و ساندرلند به طور متوسط میزان عفونت روزانه بیش از 5 مورد جدید در 100000 نفر را گزارش می کنند ، در حالی که روتلند و Isle of Wight به طور متوسط کمتر از 1 نشان می دهند.
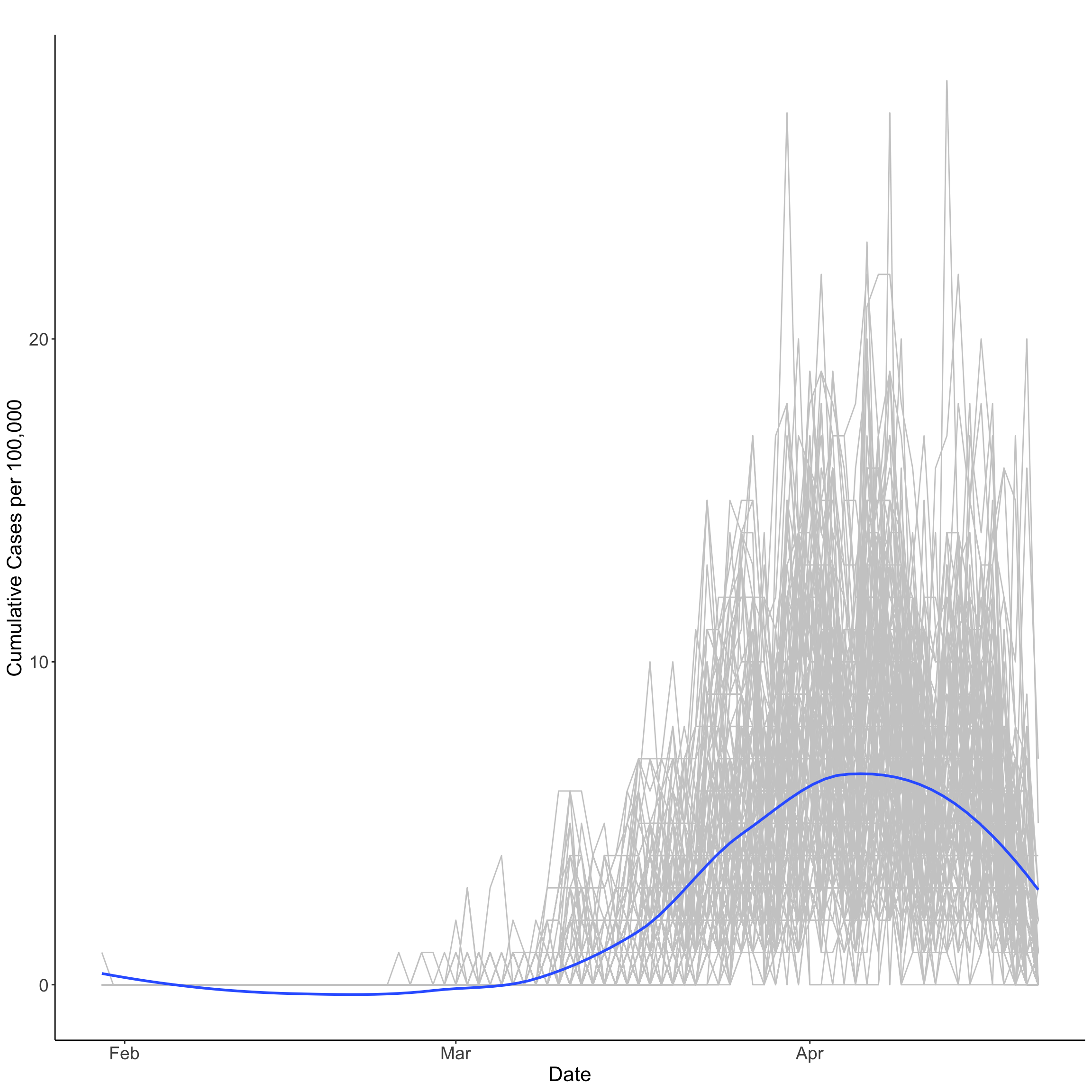
میانگین زمانی تجربی
میانگین زمانی تجربی برای یک مجموعه داده را می توان با میانگین در مکانهای مکانی برای یک نقطه زمانی بدست آورد. در مورد ما ، ما می توانیم میانگین زمانی تجربی را با میانگین نرخ موارد جدید COVID-19 بر روی UTLA به روز محاسبه کنیم. میانگین زمانی تجربی در زیر اوج 8. 32 تعداد موارد جدید در 100000 نفر در 7 آوریل ترسیم شده است ، برای آخرین مشاهده گزارش در داده های ما به طور پیوسته به 0. 35 کاهش می یابد. یعنی 21 آوریل.
توجه داشته باشید که میانگین زمانی تجربی از طریق اتصالات رگرسیون چند جمله ای محلی صاف می شود. از این رو مقادیر زیر صفر بین فوریه و مارس گزارش شده است.
10. 5. 2. 2 وابستگی
وابستگی مکانی
همانطور که می دانیم وابستگی مکانی به رابطه مکانی مقادیر متغیر برای یک جفت مکان در فاصله مشخصی از هم اشاره دارد ، به طوری که برای جفت مشاهدات به طور تصادفی مشابه (یا کمتر مشابه) است. الگوهای وابستگی مکانی ممکن است با گذشت زمان تغییر کند. در مورد الگوهای شیوع بیماری وابستگی مکانی می تواند خیلی سریع تغییر کند و موارد جدید ظاهر می شوند و اقدامات فاصله اجتماعی اجتماعی انجام می شود. فصل 6 نحوه اندازه گیری وابستگی مکانی در زمینه داده های مکانی را نشان می دهد.
چالش 1: چگونگی تغییر وابستگی مکانی با گذشت زمان را اندازه گیری کنید. نکته: I Moran's I را در مورد میزان موارد جدید Covid-19 (یعنی N_Covid19_R در قاب داده COVID19) در نقاط زمانی چندگانه محاسبه کنید.
توجه: به یاد بیاورید که مشکل نادیده گرفتن وابستگی به خطاها هنگام انجام رگرسیون OLS این است که خطاهای استاندارد حاصل و خطاهای استاندارد پیش بینی نامناسب هستند. در مورد وابستگی مثبت ، که شایع ترین مورد در داده های مکانی و زمانی است (به یاد بیاورید قانون Tobler) ، خطاهای استاندارد و خطاهای استاندارد پیش بینی دست کم گرفته می شوند. این درصورتی است که وابستگی نادیده گرفته می شود ، و در نتیجه این احساس نادرست از اینکه واقعاً تخمین ها و پیش بینی ها چقدر خوب هستند ، ایجاد می شود.
وابستگی موقتی
در مورد داده های مکانی ، وابستگی نیز می تواند در داده های زمانی وجود داشته باشد. وابستگی موقتی یا همبستگی زمانی زمانی وجود دارد که مقدار متغیر در زمان (t ) به مقدار (های) آن در (T-1 ) وابسته باشد. انتظار می رود مشاهدات اخیر بیشتر در مشاهدات موجود تأثیر بیشتری داشته باشد. تفاوت اساسی بین وابستگی زمانی و مکانی در این است که وابستگی زمانی یک طرفه است (یعنی مشاهدات گذشته فقط می تواند بر مشاهدات فعلی یا آینده تأثیر بگذارد اما به طور معکوس) ، در حالی که وابستگی مکانی چند جهته است (یعنی مشاهده در یک واحد مکانی می تواند تحت تأثیر قرار بگیرد و تحت تأثیر مشاهدات قرار گیرددر چندین واحد مکانی).
قبل از اندازه گیری وابستگی زمانی سری زمانی ما است ، یک شیء سری زمانی باید با یک تمبر زمانی و فرکانس چرخه داده شود. فرکانس چرخه به زمان تکرار یک الگوی فصلی اشاره دارد. ما یک سری زمانی از تعداد کل موارد جدید COVID-19 را در هر 100000 در نظر می گیریم (به عنوان مثال ما به طور روزانه مواردی را بیش از UTLAS) و فرکانس تعیین شده به 7 برای بازتاب چرخه های هفتگی در نظر می گیریم. بنابراین ما به یک قاب داده ای از طول 71 پایان می دهیم.
روش های مختلفی برای آزمایش همبستگی زمانی وجود دارد. یک روش آسان برای محاسبه ضریب همبستگی بین یک سری زمانی که در زمان (t ) اندازه گیری می شود و تاخیر آن در زمان اندازه گیری می شود (T-1 ). در زیر ما همبستگی زمانی را در نرخ موارد جدید COVID-19 در هر 100000 نفر اندازه گیری می کنیم. همبستگی 0. 97 بازگردانده شده است که نشانگر همبستگی مثبت بالایی است. یعنی تعداد گذشته (کم) موارد جدید COVID-19 در هر 100000 نفر تمایل به ارتباط با تعداد بیشتری از موارد جدید COVID-19 را دارند. از آزمون دوربین واتسون اغلب برای آزمایش همبستگی در مدلهای رگرسیون استفاده می شود.
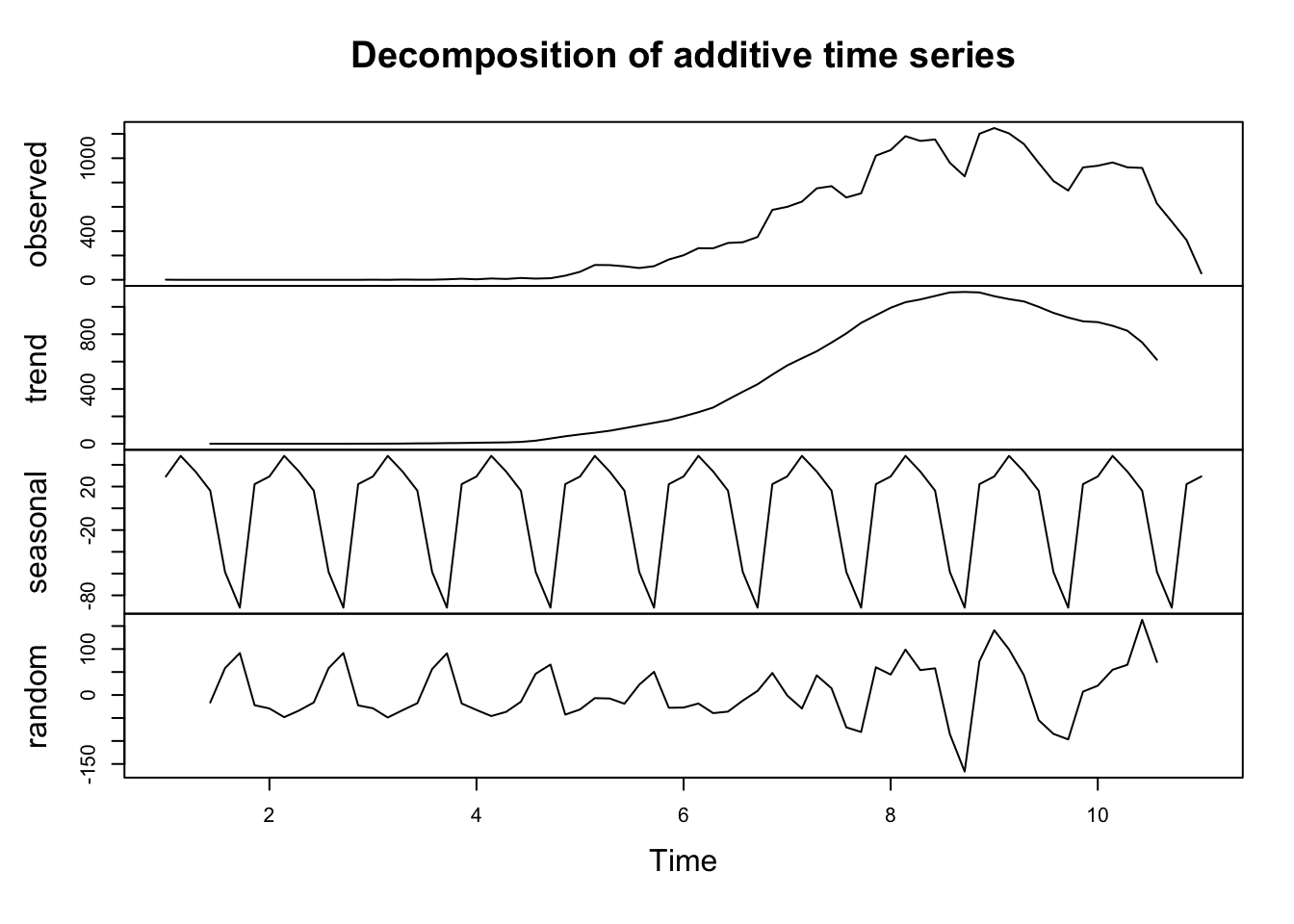
اجزای سری زمانی
علاوه بر همبستگی زمانی ، برای تجزیه و تحلیل سری زمانی ، اجزای تشکیل دهنده آن بسیار مهم است. یک سری زمانی به طور کلی توسط سه مؤلفه اصلی تعریف می شود:
روند: هنگامی که افزایش طولانی مدت یا کاهش داده ها وجود داشته باشد ، روند وجود دارد.
فصلی: یک الگوی فصلی زمانی وجود دارد که یک سری زمانی تحت تأثیر عوامل فصلی باشد و از فرکانس ثابت و شناخته شده برخوردار باشد. چرخه های فصلی ممکن است در فواصل زمانی مختلف مانند زمان روز یا زمان سال رخ دهد.
چرخه ای (تصادفی): چرخه ای وجود دارد که نمایش داده ها افزایش می یابد و سقوط می کند که از فرکانس ثابت نیستند.
برای درک و مدل سازی یک سری زمانی ، این مؤلفه ها باید در یک مدل رگرسیون شناسایی و مناسب شوند. ما این مؤلفه ها را با تجزیه سری زمانی خود برای کل موارد COVID-19 در زیر نشان می دهیم. طرح بالا داده های مشاهده شده را نشان می دهد. توطئه های بعدی روند ، اجزای فصلی و تصادفی تعداد کل موارد COVID-19 را در یک تناوب هفتگی نشان می دهد. آنها یک روند واضح و الگوی فصلی وارونه را نشان می دهند. این ایده که ما می توانیم داده ها را برای استخراج اطلاعات و درک فرآیندهای زمانی تجزیه کنیم ، برای درک مفهوم توابع پایه برای مدل سازی داده های فضا-زمانی ، که در بخش بعدی معرفی خواهد شد ، مهم است.
برای معرفی خوب تجزیه و تحلیل سری زمانی در R ، به Hyndman و Athanasopoulos (2018) و DataCamp مراجعه کنید.
10. 6 مدل سازی داده های فضا-زمانی
با داشتن درک برخی از الگوهای مکانی-زمانی COVID-19 از طریق اکتشاف داده ها ، ما آماده هستیم تا روابط ساختاری بین میزان عفونت های جدید و عوامل زمینه محلی را از طریق مدل سازی رگرسیون در سراسر UTLAS بررسی کنیم. به طور خاص ما تعداد موارد جدید را در هر 100000 نفر برای گرفتن میزان عفونت های جدید و تنها یک عامل متنی در نظر می گیریم. یعنی سهم جمعیتی که از بیماری طولانی مدت یا معلولین رنج می برند. ما برخی از مدلهای آماری اساسی ، به شکل رگرسیون خطی و مدلهای خطی تعمیم یافته را در نظر خواهیم گرفت تا وابستگی های فضایی-زمانی در داده ها را به خود اختصاص دهیم. توجه داشته باشید که ما ساختارهای پیچیده تری را بر اساس مدلهای سلسله مراتبی یا مدلهای رگرسیون وزنی مکانی و زمانی که می تواند قدم طبیعی به جلو باشد ، در نظر نمی گیریم.
به عنوان هر رویکرد مدل سازی ، مدل سازی آماری فضایی-زمانی سه هدف اصلی دارد:
پیش بینی مقادیر متغیر نتیجه مشخص در برخی از مکان ها در فضا در مدت زمان مشاهدات و ارائه اطلاعات در مورد عدم اطمینان از این پیش بینی ها.
انجام استنتاج آماری در مورد تأثیر پیش بینی کننده ها بر متغیر نتیجه در حضور وابستگی مکانی و زمانی. وت
پیش بینی مقادیر آینده متغیر نتیجه در برخی از مکان ها ، ارائه اطلاعات در مورد عدم اطمینان پیش بینی.
10. 6. 1 شهود
ایده اصلی در مورد آنچه در زیر می آید استفاده از یک مدل رگرسیون آماری اساسی برای درک رابطه بین سهم عفونت های جدید COVID-19 و سهم جمعیت مبتلا به بیماری طولانی مدت است ، که به وابستگی های فضایی و زمانی است. ما آنچه را که به عنوان یک مدل رگرسیون سطح روند شناخته می شود ، در نظر خواهیم گرفت که فرض می کند وابستگی های فضایی و زمانی را می توان با استفاده از مؤلفه های "روند" در نظر گرفت و به عنوان پیش بینی کننده در مدل گنجانید. به طور رسمی مدل رگرسیون را در زیر در نظر می گیریم که به دنبال روندهای مکانی و زمانی است.
[y (s_ ، t_) = beta_ + beta_x (s_ ، t_) + e (s_ ، t _) ]
جایی که ( beta_ ) رهگیری است و ( beta_ ) مجموعه ای از ضرایب رگرسیون مرتبط با (x (s_ ، t _) ) را نشان می دهد. (k ) تعداد متغیرهای متغیر را در مکان مکانی (s_ ) و زمان (t_ ) نشان می دهد. (e ) خطاهای رگرسیون را نشان می دهد که فرض می شود از توزیع عادی پیروی می کنند. تفاوت اصلی در مورد آراء در نظر گرفته شده در فصل های قبلی ، ترکیب فضا و زمان در کنار هم است. همانطور که از بخش قبلی آموخته ایم ، این پیامدهایی دارد که اکنون ما دو منبع وابستگی داریم: همبستگی مکانی و زمانی و همچنین اجزای فصلی و روند. این امر پیامدهای مربوط به مدل سازی را دارد زیرا اکنون باید همه این مؤلفه ها را در صورتی که بخواهیم بین (y ) و (x ) برقرار کنیم ، حساب کنیم.
پیامد اصلی این است که چگونه ما مجموعه متغیرهای متغیر را که توسط (x ) نشان داده شده است ، در نظر می گیریم. سه نوع کلیدی را می توان شناسایی کرد:
متغیرهای متغیر مکانی ، متغیر زمانی: این ویژگی هایی هستند که ممکن است در فضا متفاوت باشند اما به طور موقت ثابت باشند ، مانند مسافت های جغرافیایی.
متغیرهای متغیر فضایی ، متغیر زمانی: این ویژگی هایی هستند که در فضا متفاوت نیستند اما با گذشت زمان تغییر می کنند. وت
متغیرهای متناوب مکانی ، متناوب و متغیر: اینها ویژگی هایی هستند که در هر دو فضا و زمان متفاوت هستند.
توجه داشته باشید که آنچه متفاوت یا متغیر است به مقیاس مکانی و زمانی تجزیه و تحلیل بستگی دارد.
ما همچنین می توانیم "توابع پایه" فضایی-زمانی را در نظر بگیریم. توجه داشته باشید که این یک مفهوم مهم برای بقیه فصل است. توابع پایه پس چیست؟اگر فکر می کنید که داده های فضایی و زمانی مجموعه ای پیچیده از منحنی ها یا سطوح موجود در فضا را نشان می دهد ، توابع پایه نمایانگر مؤلفه هایی هستند که می توان این مجموعه از منحنی ها را تجزیه کرد. به این معنا ، توابع پایه به روشی مشابه عمل می کنند ، همانطور که تجزیه سری زمانی که در بالا در نظر گرفته می شود ، می توان داده های سری زمانی را به یک روند ، اجزای فصلی و تصادفی تجزیه کرد و از جمع آنها می توان برای نشان دادن مسیر زمانی مشاهده شده استفاده کرد. توابع پایه یک روش مؤثر برای ترکیب وابستگی های فضایی-زمانی ارائه می دهد. بنابراین ، توابع پایه هدف اصلی حسابداری از وابستگی های مکانی و زمانی را دارند زیرا ماتریس های وزن مکانی یا تاخیر زمانی به حسابداری همبستگی مکانی در مدلهای مکانی و همبستگی زمانی در تجزیه و تحلیل سری زمانی کمک می کند.
به عنوان ضرایب رگرسیون استاندارد، توابع پایه از طریق ضرایب (یا وزن ها) به (y) مربوط می شوند. تفاوت این است که ما معمولاً فرض می کنیم که توابع پایه شناخته شده هستند در حالی که ضرایب تصادفی هستند. نمونه هایی از توابع پایه شامل چند جمله ای، اسپلاین ها، موجک ها، سینوس ها و کسینوس ها هستند، بنابراین ترکیب های خطی مختلفی که می توانند برای استنتاج وابستگی های مکانی-زمانی بالقوه در داده ها استفاده شوند. این شبیه به مدل های یادگیری عمیق است که در آن موارد، برای مثال، یک تصویر ارائه می کنید و مدل یک طبقه بندی پیکسل ها را ارائه می کند. اما معمولاً نمی دانید که طبقه بندی چه چیزی را نشان می دهد (از این رو آنها به عنوان جعبه های سیاه شناخته می شوند!) بنابراین تجزیه و تحلیل بیشتری در مورد طبقه بندی لازم است تا بفهمیم مدل سعی کرده چه چیزی را ثبت کند. اساساً توابع پایه، توابع نرم تری برای نمایش داده های مشاهده شده هستند و هدف آنها به دست آوردن تنوع مکانی و زمانی در داده ها و همچنین وابستگی آنهاست.
برای کاربرد خود، ما با در نظر گرفتن یک مدل رگرسیون OLS اولیه با توابع پایه زیر برای محاسبه ساختارهای مکانی-زمانی شروع می کنیم:
- میانگین کلی؛
- خطی در lon-coordinate;
- خطی در lat-coordinate;
- روند روزانه زمان خطی؛
- توابع پایه مکانی-زمانی اضافی که در زیر ارائه شده است. و
این توابع پایه به عنوان متغیرهای مستقل در مدل رگرسیون گنجانده شده اند. علاوه بر این، ما همچنین سهم جمعیتی را که از بیماری طولانی مدت رنج می برند، در نظر می گیریم، زیرا می دانیم که ارتباط زیادی با تعداد تجمعی موارد COVID-19 دارد. سهم جمعیتی که از بیماری طولانی مدت رنج می برند، به عنوان متغیرهای کمکی متغیر مکانی، زمانی-غیر متغیر با توجه به داده های سرشماری سال 2011 ادغام می شود.
10. 6. 2 برازش مدل های مکانی-زمانی
همانطور که در آغاز این فصل مشخص شد ، ما از چارچوب FRK تهیه شده توسط Cressie و Johannesson (2008) استفاده می کنیم. این یک مقیاس پذیر ، متکی به استفاده از یک مدل جلوه های تصادفی مکانی (که با آن ما آشنایی داریم) متکی است و با استفاده از بسته FRK می توان به راحتی در R پیاده سازی کرد (Zammit-Mangion and Cressie 2017). در این چارچوب ، خطاهای همبستگی مکانی با استفاده از ترکیبی خطی از توابع پایه مکانی تجزیه می شوند ، که به طور موثری به موضوعات وابستگی مکانی و غیرقانونی و غیر استیج می پردازد. مشخصات توابع پایه مکانی یک مؤلفه اصلی مدل است و می توان آنها را به صورت خودکار یا توسط کاربر از طریق بسته FRK تولید کرد. ما از توابع تولید شده به طور خودکار استفاده خواهیم کرد. در حالی که همانطور که متوجه خواهیم شد تفسیر آنها دشوار است ، توابع تولید شده توسط کاربر نیاز به درک بیشتری از ساختار مکانی و زمانی Covid-19 دارند که فراتر از محدوده این فصل است.
داده ها را تهیه کنید
اولین قدم برای ایجاد یک قاب داده با متغیرهایی که برای تجزیه و تحلیل در نظر خواهیم گرفت. ما ابتدا هندسه ها را برای تبدیل COVID19_SPT از یک شیء ویژگی ساده به یک قاب داده حذف می کنیم و سپس سهم جمعیت بیماری طولانی مدت را محاسبه می کنیم.
توابع پایه
اکنون مجموعه ای از توابع پایه را می سازیم. می توان با استفاده از عملکرد Auto_Basis از بسته FRK ساخته شد. این عملکرد به عنوان آرگومان ها انجام می شود: داده ها ، nres (که تعداد "قطعنامه ها" یا جمع آوری برای ساخت) است. و نوع عملکرد پایه برای استفاده. ما یک وضوح واحد از عملکرد پیش فرض پایه شعاعی گاوسی را در نظر می گیریم.
توابع پایه را به قاب داده اضافه کنید
سپس یک قاب داده را برای مدل رگرسیون تهیه می کنیم و وزنهای استخراج شده از توابع پایه را اضافه می کنیم. این وزن ها به عنوان متغیرهای متغیر در مدل ما وارد می شوند. توجه داشته باشید که تعداد حاصل از عملکردهای پایه نه است. با اجرای Colnames (ها) کاوش کنید. در زیر ما فقط متغیرهای مربوطه را برای مدل خود انتخاب می کنیم.
رگرسیون خطی متناسب است
اکنون ما یک مدل خطی را با استفاده از LM از جمله به عنوان متغیرهای متغیر ، عرض جغرافیایی ، روز ، سهم جمعیت بیمار طولانی مدت و نه عملکرد پایه قرار می دهیم.
به یاد بیاورید که عرض جغرافیایی از استوا به شمال/جنوب اشاره دارد و طول جغرافیایی به غرب/شرق از گرینویچ اشاره دارد. در شمال به معنای نمره عرض جغرافیایی بالاتر است. غرب بیشتر به معنای نمره طول جغرافیایی بالاتر است. نمرات لیورپول (53. 4084 ° N ، 2. 9916 ° W) از این رو بالاتر از لندن است (51. 5074 ° N ، 0. 1278 ° W). این برای تفسیر مفید خواهد بود.
ضرایب برای متغیرهای مکانی و زمانی صریح مشخص شده و سهم جمعیت بیمار طولانی مدت همه از نظر آماری معنی دار هستند. تفسیر ضرایب رگرسیون طبق معمول است. یعنی افزایش یک واحد در یک متغیر متغیر مربوط به یک واحد در متغیر وابسته است. به عنوان مثال ، ضریب جمعیت طولانی مدت بیماری نشان می دهد که UTLA ها با سهم بیشتری از جمعیت بیمار طولانی مدت در یک درصد تمایل به 709 مورد جدید Covid-19 در 100000 نفر دارند! به طور متوسط. ضریب برای روز ، وابستگی زمانی منفی قوی را با تعداد کمتری از موارد جدید در 100000 نفر نشان می دهد که با گذشت زمان حرکت می کنیم. ضریب Latutide نشان می دهد که ما به شمال حرکت می کنیم ، تعداد موارد جدید Covid-19 در هر 100000 نفر تمایل به بالاتر بودن دارند اما اگر به سمت غرب حرکت کنیم ، پایین تر هستند.
در حالی که به طور کلی مدل درک برخی از ساختار مکانی و زمانی گسترش COVID-19 را ارائه می دهد ، تناسب کلی مدل نسبتاً ضعیف است. (r^) نشان می دهد که این مدل تنها 5 ٪ از تنوع گسترش موارد Covid-19 را توضیح می دهد. همچنین ، به جز یک ، ضرایب مرتبط با توابع پایه از نظر آماری ناچیز هستند. یک مسئله کلیدی که تاکنون نادیده گرفته ایم این واقعیت است که متغیر وابسته ما یک شمارش است و بسیار ناچیز است - به بخش [8. 4 تجزیه و تحلیل اکتشافی] مراجعه کنید.
چالش 2: یک مدل را تنها با اجزای مکانی (یعنی طولانی و لات) یا فقط اجزای زمانی (روز) کشف کنید. چه مدلی بزرگترین (r^) را برمی گرداند؟
رگرسیون پواسون
یک مدل رگرسیون پواسون یک چارچوب مناسب تر برای رسیدگی به این موضوعات فراهم می کند. ما این کار را برای یک مدل خطی کلی (یا GLM) انجام می دهیم که عملکرد خانواده را به عنوان پواسون مشخص می کند.
به نظر می رسد این مدل مناسب تر از داده ها را فراهم می کند زیرا میانگین باقیمانده های انحرافی (-6. 3) از مدل رگرسیون خطی کوچکتر است (-27. 51). و همه ضرایب مثبت و از نظر آماری معنی دار هستند. با این حال ، مدل پواسون فرض می کند که میانگین و واریانس موارد COVID-19 یکسان است. اما ، با توجه به توزیع متغیر وابسته ما ، واریانس آن احتمالاً بیشتر از میانگین است. این بدان معنی است که داده ها "بیش از حد" نمایش داده می شوند. چگونه این را بدانیم؟برآورد پراکندگی با نسبت انحراف به کل درجه آزادی (تعداد نقاط داده منهای تعداد متغیرهای متغیر) ارائه شده است. در این حالت برآورد پراکندگی:
که به وضوح بیشتر از 1 است! یعنی داده ها بیش از حد اسپری شده اند.
رگرسیون quasipoisson
رویکردی برای پاسخگویی به بیش از حد استفاده از quasipoisson هنگام تماس با GLM است. مدل شبه پیزون فرض می کند که واریانس متناسب با میانگین است و ثابت بودن تناسب پارامتر بیش از حد پراکندگی است.
رگرسیون دوتایی منفی
خروجی مدل نشان دهنده پیشرفت عمده از نظر متناسب با مدل به عنوان انحراف باقیمانده (959940) و میانگین باقیمانده های انحراف (-6. 380) بدون تغییر است. یک روش جایگزین یک مدل دوتایی منفی (NBM) است. این مدل ها فرض برابری بین میانگین و واریانس را آرام می کند. ما NBM را با استفاده از عملکرد GLM. NB از بسته انبوه تخمین می زنیم.
از جمله تعامل
به طور مشابه ، خروجی مدل هیچ پیشرفت عمده ای در توضیح تنوع مکانی-زمانی در گسترش COVID-19 نشان نمی دهد. ممکن است ما به یک استراتژی متفاوت نیاز داشته باشیم. بیایید NBM را شامل شود که شامل اصطلاحات تعامل بین اصطلاحات مکانی و زمانی (یعنی طول جغرافیایی ، عرض جغرافیایی و روز) باشد. ما می توانیم این کار را با برآورد مدل زیر C_COVID19_R انجام دهیم~(طولانی + لات + روز)^2 + lt_illness +.
این مدل با بازگرداندن کمی در انحراف باقیمانده و نمره AIC به یک مدل بهتر منجر می شود. جالب اینجاست که این امر همچنین به طور قابل توجهی آماری آماری را برای اصطلاحات تعامل بین طول جغرافیایی و عرض جغرافیایی (طولانی: لات) و عرض جغرافیایی و روز (LAT: DAY) باز می گرداند. اولی نشان می دهد که وقتی یک درجه به شمال و غرب حرکت می کنیم ، تعداد موارد جدید در 2 مورد افزایش می یابد. دومی نشان می دهد که UTLAS در غرب انگلیس تمایل دارد با گذشت زمان تعداد کمتری از موارد را گزارش کند.
شما می توانید با اجرای (بعد از حذف #) خروجی را برای کلیه مدلهای تخمین زده شده در بالا گزارش کنید:
10. 6. 2. 1 مقایسه مدل
برای مقایسه مدل های رگرسیون بر اساس مشخصات و فرضیات مختلف ، مانند موارد گزارش شده در بالا ، ممکن است بخواهید رویکرد اعتبار سنجی متقاطع مورد استفاده در جریان فصل 4 را در نظر بگیرید. یک رویکرد آسان اگر می خواهید حس سریع مدل را بدست آورید ، می توانید به همبستگی بین مقادیر مشاهده شده و پیش بینی شده متغیر وابسته نگاه کنید. برای مدل های ما ، ما می توانیم با اجرای این کار به این هدف برسیم:
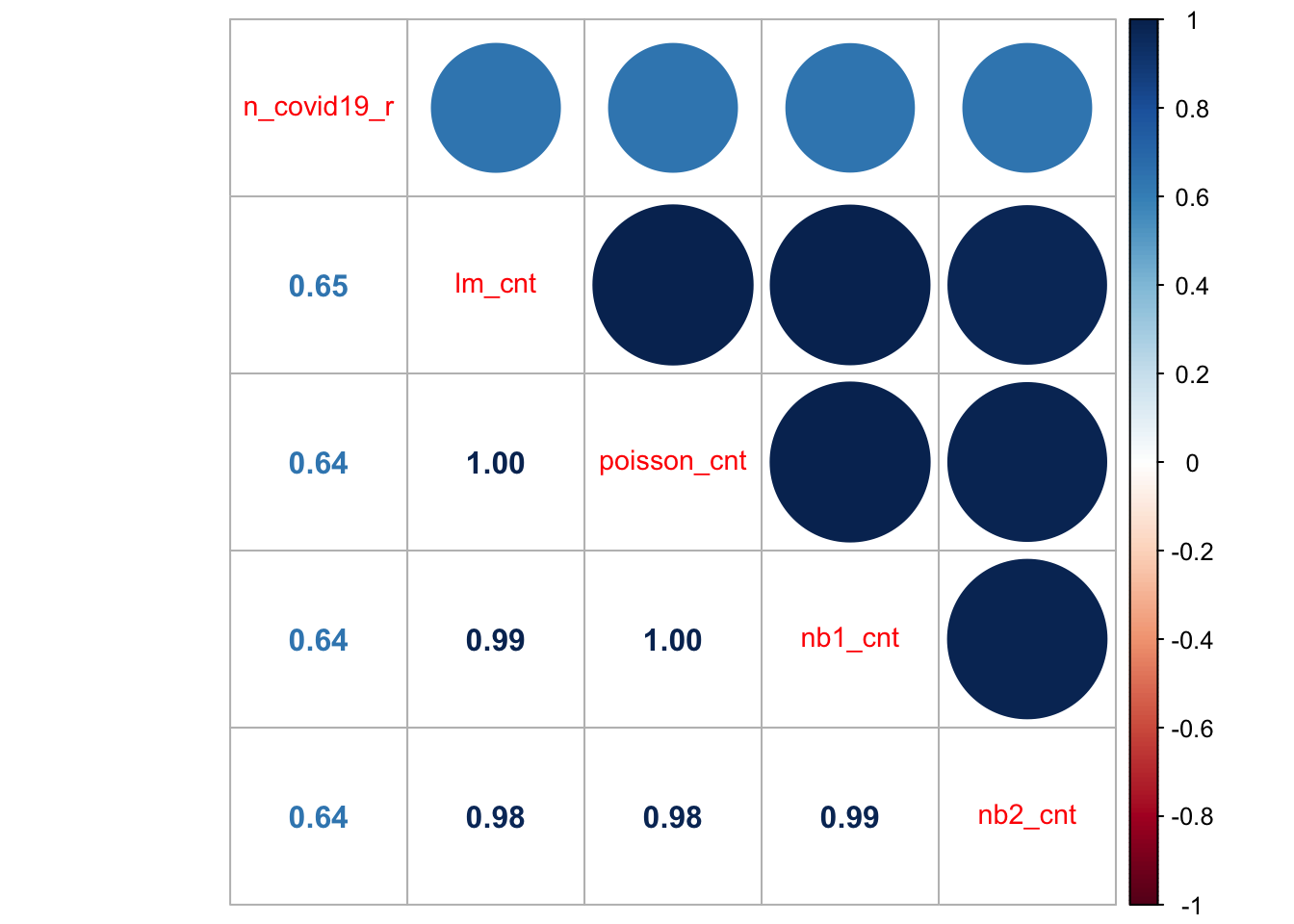
هیچ یک از مدل ها در پیش بینی تعداد مشاهده شده موارد جدید Covid-19 کار بزرگی انجام نمی دهند. آنها ضرایب همبستگی بین 0. 23 تا 0. 24 و درجه بالای همبستگی بین آنها را نشان می دهند. بخشی از تکالیف یافتن راه هایی برای بهبود این مدل های اولیه خواهد بود. آنها فقط باید به عنوان نقطه شروع در نظر گرفته شوند.
چالش 3: راه هایی برای دستیابی به مدل بهتر مدل پیدا کنید. نکته: روشهای آسان بسیار ساده ای برای پیشرفت قابل توجهی وجود دارد. یک گزینه حذف تمام صفرها از متغیر وابسته C_COVID19_R است. اگر بخواهیم الگوهای فضایی و زمانی شیوع را درک کنیم ، آنها به احتمال زیاد بر توانایی مدل در پیش بینی مقادیر مثبت مورد توجه قرار می گیرند. ایده دوم این است که تمام صفرها را از متغیر وابسته خارج کنید و علاوه بر این از ورود به سیستم آن برای مدل رگرسیون استفاده کنید. ایده سوم شامل متغیرهای توضیحی تر است. به دنبال عواملی باشید که می تواند تنوع مکانی و زمانی شیوع فعلی COVID-19 را توضیح دهد. به دنبال فرضیه ها / شواهد حکایتی از روزنامه ها و رسانه های اجتماعی باشید. ایده چهارم این است که برای COLLINEARITY بررسی کنید. با توجه به شیوه ایجاد توابع پایه ، احتمالاً Collinearity مسئله ای خواهد بود. البته چک کردن برای همسایگی ، تناسب مدل موجود را بهبود نمی بخشد ، اما اگر استنتاج آماری یک هدف اصلی باشد - که در این حالت وجود دارد ، حذف شرایط Collinear مهم است. الان به تو!
منابع
Cressie ، Noel و Gardar Johannesson. 2008. "kriging رتبه ثابت برای مجموعه داده های مکانی بسیار بزرگ."مجله انجمن آماری سلطنتی: سری B (روش آماری) 70 (1): 209-26.
گابادینیو ، الکسیس ، گیلبرت ریتشارد ، ماتیاس استودر و نیکلاس اس مولر. 2009. "داده های دنباله استخراج معادن در R با بسته Traminer: راهنمای کاربر."ژنو: گروه اقتصاد سنجی و آزمایشگاه جمعیت شناسی ، دانشگاه ژنو.
Hyndman ، Rob J و George Athanasopoulos. 2018. پیش بینی: اصول و عمل. otexts.
Lovelace ، Robin ، Jakub Nowosad و Jannes Muenchow. 2020. مقدمه ای برای یادگیری آماری. جلد112. CRC Press ، سری R. https://geocompr. robinlovelace.net.
Pebesma ، Edzer و دیگران. 2012. "Spacetime: داده های فضایی-زمانی در R."مجله نرم افزار آماری 51 (7): 1-30.
ویکل ، کریستوفر K ، اندرو زامیت-مانگون و نوئل کریسی. 2019. آمار فضایی-زمانی با r. مطبوعات CRC.
Zammit-Mangion ، Andrew و Noel Cressie. 2017. "FRK: یک بسته R برای پیش بینی مکانی و مکانی-زمانی با مجموعه داده های بزرگ."arxiv preprint arxiv: 1705. 08105.
این یادداشت بخشی از تجزیه و تحلیل فضایی و تجزیه و تحلیل فضا-زمان است-مدل سازی فضایی-زمانی توسط Francisco Rowe دارای مجوز Creative Commons Attribution-Noncommercial-Sharealike 4. 0 مجوز بین المللی است.
You can install package mypackage by running the command install.packages("mypackage") on the R prompt or through the Tools >بسته ها را نصب کنید. منو در RSTUDIO.↩︎
بهترین استراتژی معاملات...
ما را در سایت بهترین استراتژی معاملات دنبال می کنید
برچسب :
نویسنده : صدرا ذوالریاستین
بازدید : 60
